
In my free time, I’m exploring the MEAN stack. My previous employer had a few teams running Node.JS & MongoDB and the resulting products and team-velocity looked slick!
I’m following “Web Development with MongoDB and Node.js” by Jason Krol.
Getting Started with MongoDB
For this play-instance, I’m using a t2.micro Ubuntu instance (free-tier eligible) on AWS.
The installation instructions mongoDB provides are way easy to follow and get setup easily enough. Tailing the log in /var/log/mongodb will show when the service is up and running:
2018-04-03T22:00:09.104+0000 I STORAGE [initandlisten] createCollection: local. startup_log with generated UUID: 6918c25c-94fb-4c41-8bb0-80e3e1fd7630
2018-04-03T22:00:09.114+0000 I FTDC [initandlisten] Initializing full-time diagnostic data capture with directory ‘/var/lib/mongodb/diagnostic.data’
2018-04-03T22:00:09.114+0000 I NETWORK [initandlisten] waiting for connections on port 27017
Creating Databases
To initiate a mongo client, just type in mongo, once the service is running.
For Postgres, this would be a quick SQL statement:
CREATE DATABASE “project-next”
WITH
OWNER = postgres
ENCODING = ‘UTF8’
CONNECTION LIMIT = -1;\
For MongoDB, ummm… you use the database to actually create it.
> use project-next
switched to db project-next> show dbs
admin 0.000GB
config 0.000GB
local 0.000GB
But the DB won’t show until it has a table… err collection.
Creating Tables Collections
For Postgres, this is where schema definition is important. Which columns should not be null? What’s the data that could be stored in each? What should the primary key be? All these questions need to be answered before creating a table.
CREATE TABLE public.projects
(
uuid uuid NOT NULL,
“project-name” character varying(255) NOT NULL,
status character varying(255) NOT NULL,
created_dt date,
updated_dt date,
PRIMARY KEY (uuid)
)
For MongoDB, tables are called “Collections”. And yes, you can kind of pre-define them if you want – or you can just start inserting data. Since I want to follow the same restrictions as the Postgres table I created, I need to define a jsonSchema to follow for the collection:
> db.createCollection(“projects”, {validator: {$jsonSchema: {bsonType: “object”,required: [ “projectname”, “status” ],properties: {projectname: {bsonType: “string”,description: “not-null string holding name of project”},status: {bsonType: “string”,description: “non-null string holding status of project”},created_dt: {bsonType: “date”,description: “date when the project was created”},updated_dt: {bsonType: “date”,description: “date in which the project was last updated”}}}}})
{ “ok” : 1 }
Querying the Schema definition
In Postgres, I can run a SQL statement to get back how the projects table is setup:
select column_name, is_nullable, data_type, character_maximum_length
from information_schema.columns
where table_name =’projects’;
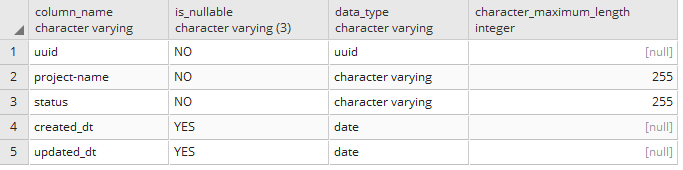
For Mongo, I can run a command to get collection info, and pass in a filter for the collection I want:
> db.getCollectionInfos({“name”:”projects”})[{“name” : “projects”,“type” : “collection”,“options” : {“validator” : {“$jsonSchema” : {“bsonType” : “object”,“required” : [“projectname”,“status”],“properties” : {“projectname” : {“bsonType” : “string”,“description” : “not-null string holding name of project”},“status” : {“bsonType” : “string”,“description” : “non-null string holding status of project”},“created_dt” : {“bsonType” : “date”,“description” : “date when the project was created”},“updated_dt” : {“bsonType” : “date”,“description” : “date in which the project was last updated”}}}}},“info” : {“readOnly” : false,“uuid” : UUID(“260d8792-8037-4c0e-bdb9-e36a30b85eb4”)},“idIndex” : {“v” : 2,“key” : {“_id” : 1},“name” : “_id_”,“ns” : “test.projects”}}]
You’ll notice here that I didn’t define an ID (shown as UUID for the postgres table creation), but one is shown when I get the mongoDB collection (in blue). For MongoDB, each collection includes an _id field by default – auto-generated as an ObjectID, one of the BSON types. This field is setup as the primary key and is automatically indexed. We can choose to over-ride this default though in the schema definition or in our insert statements. This is useful, for example, for migrations where the primary key should be preserved as much as possible. Or in cases where the primary key in meaningful outside of the data-layer.
Inserting Rows documents
For Postgres, we can just list the data we want to insert in order. No column name needed.
insert into projects values (uuid_generate_v4(),‘learn MongoDB’,‘In Progress’,current_date,current_date);
For MongoDB, it acts more like a key:value pair. Each attribute name should be included if they have a corresponding value.
db.projects.insert({projectname:’learn MongoDB’, status:’In Progress’, created_dt: new Date(), updated_dt: new Date()})
Running queries
Let’s start with a simple select clause based on the data we just inserted:
select *
from projects

And in MongoDB:
> db.projects.find().pretty()
{
“_id” : ObjectId(“5ac4ec04210abcdf13c43ed7”),
“projectname” : “learn MongoDB”,
“status” : “In Progress”,
“created_dt” : ISODate(“2018-04-04T15:15:16.638Z”),
“updated_dt” : ISODate(“2018-04-04T15:15:16.638Z”)
}
The pretty() function translates the json output into a more readable format.
So that’s easy enough. How about searching for data? Through the magic of Mockaroo, I now have over thousand records in both Postgres & MongoDB.
A note about mockaroo: you’ll need to do some fancy search & replace to get the json format just right for mongoimport to work against it. For example, I had to get “new Date” functions in just the right places.
Let’s find a count of the Delayed projects. First in postgres:
select count(*) from projects
where status = ‘Delayed’
And in MongoDB:
> db.projects.find({“status”:”Delayed”}).count()
551
So, you can see the same kind of key-value pair in the find-function that we had in the insert. Easy enough.
In a future blog, I’ll get into joins and ordering.

Leave a comment